Implement the Trie Data Structure (Hard)
Good morning! Here's our prompt for today.
You may see this problem at Pinterest, Coinbase, Flatiron Health, Procore, Netskope, Lucid Software, Automattic, Blend, Bosch Global, Pagerduty, and Sonos.
Suppose you're asked during an interview to design an autocompletion system. On the client side, you have an input box. When users start typing things into the input, it should parse what's been typed and make suggestions based on that.
For example, if the user has typed "cat", we may fetch "cat", "category", and "catnip" as recommendations to display. This seems pretty simple-- we could just do a scan of all the words that start with "cat" and retrieve them. You can do this by storing the words in an array and doing a binary search in O(log n) time complexity, with n being the number of words to search through.
But what if you have millions of words to retrieve and wanted to separate the search time from vocabulary size?
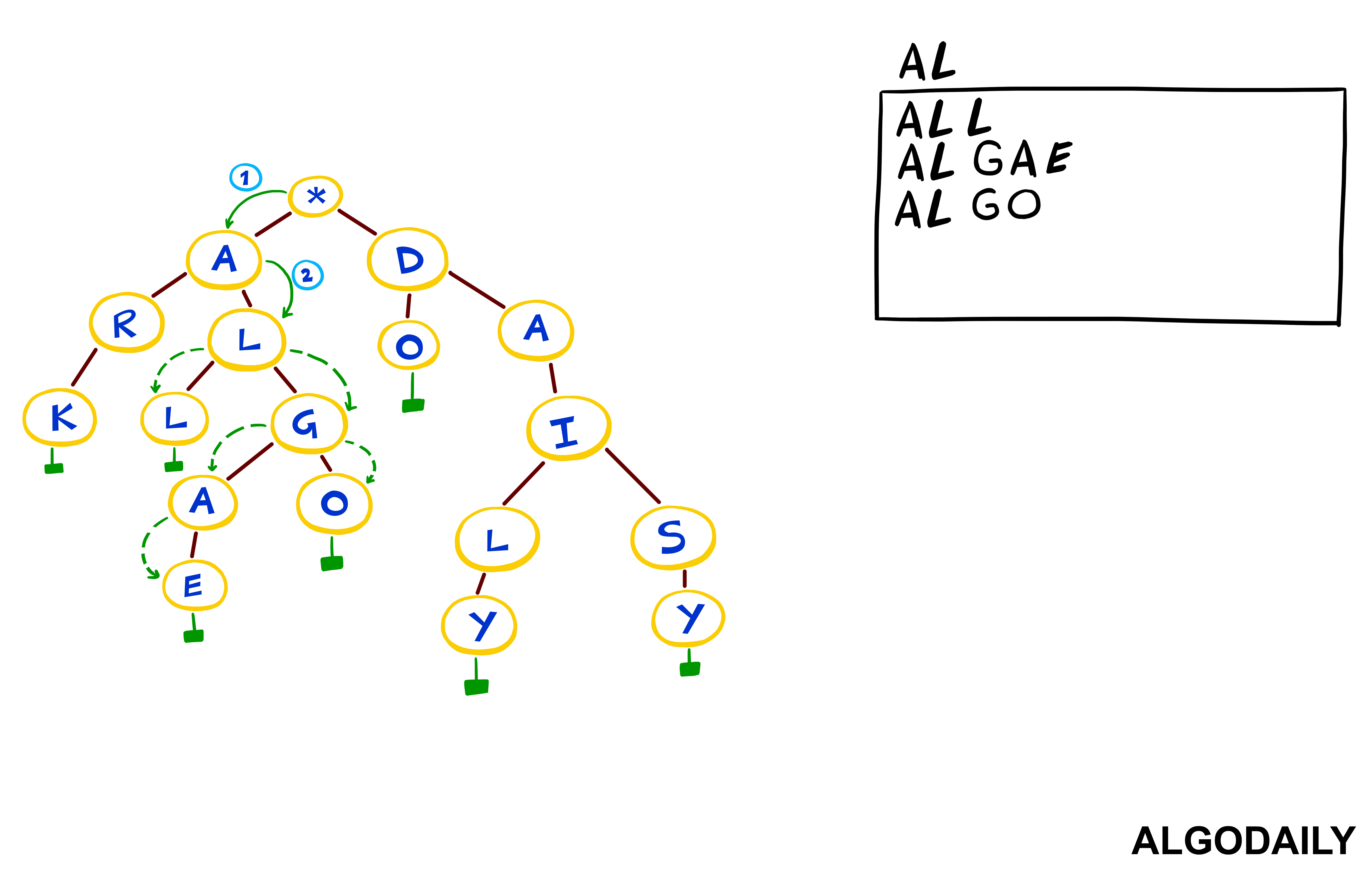
A trie (for data reTRIEval), or prefix tree, would be what you want. Let's implement one today.
We should implement:
- An
addmethod that can add words to the trie - A
searchmethod that returns the depth of a word - A
removemethod that removes the word
Constraints
- Total number of
characters(not total number ofstrings) to be inserted <=100000 - The characters will only comprise of lowercase alphabets
- Expected time complexity for add, search and delete :
O(n)n being the length of the word - Expected space complexity :
O(26 * n * N)whereNis number of strings
xxxxxxxxxxvar assert = require('assert');class Trie { // fill this class out add(val) {} search(val) {} remove(val) {}}// const trie = new Trie();// console.log(trie.add('cherry'));// console.log(trie);// console.log(trie.search('cherry'));function Node(val) { this.val = val; this.left = null; this.right = null;}// Regular binary treesvar tree1 = new Node(4);tree1.left = new Node(1);tree1.right = new Node(3);